
熊猫智能采集电脑版是一款高效易用的内容收集程序,运用独特解析核心,模仿浏览器行为处理网页信息,能区分框架与正文,创新方法实现同类页面比对,只需要设定一个样例,工具自动识别并抓取批量目标数据,直接点击想提取的部分即可完成设置,欢迎有需要的朋友下载尝试。
熊猫智能采集电脑版特色
1、多维度的收集作用,收集的目标包含文字材料、图像、flash 动态影像、保存文件等各类网络材料。准许图文混合排列目标的一同收集。准许构造繁杂的收集目标组合,准许繁杂多数据库表格,准许跨页面材料整合收集的本领。
2、针对目标收集,收集目标的材料能够是分散在多个页面(模板页面的深度嵌套访问)熊猫收集是针对目标的,一个收集目标能够包含许多需要收集的子项属性材料。这些子项属性的材料允许分散在不同的页面内,这些页面能够是需要经过若干次链接才能抵达的页面,此处所谓 “目标”,可以理解为 “(需要收集的数据的)数据组合 ” 的意思。这个数据组合的材料和范围由使用者根据实际需求自行确定,没有特定的要求。也可以将该目标范畴包含到 “标题列表页面”,这属于灵活使用的方法,在此不多做说明。灵活的使用针对目标的方法,不仅可以完成很多繁杂的收集需求,更可以让收集设置过程更为简便。
3、收集速度迅速,熊猫收集的收集速度是收集工具中最快的(之一)。不运用落后低效的正则匹配技术。也不运用第三方内置浏览器访问的技术。运用自己研发的解析引擎,完成对网页源码的仿浏览器解析。拆分网页可视化材料元素,在此基础上进行机器学习、批量收集匹配。经实际测试,是传统的正则匹配方式收集速度的 2~5 倍。是基于第三方内置浏览器收集速度的 10~20 倍。
4、结果数据完整度高,实际收集过程中,由于目标页面存在丰富的材料页面版式的情况,此时就需要运用熊猫独有的 “多模板功能”,才能完成完整的收集。同时,看起来页面版面一致的情况下,也可能会存在因为页面内部的少量差异而收集匹配失败,此时就需要收集器具有智能容错本领。智能容错本领,是衡量一个收集器是否成熟的基本标志之一。熊猫追求的是收集结果 100% 的完整。包括有效页面 100% 的收集,页面中收集的材料 100% 的收集。只要设置恰当,不会出现收集结果遗漏的情况。—— 只有熊猫才能让结果如此完整。
5、JS 解析的自动判断识别,现在很多网页都采用了 ajax 网页材料动态生成技术。此时仅仅依靠网页源码,并不能获取需要的有效材料。此时就需要对被收集的页面执行 JavaScript(JS)解析,获取 JS 执行后的结果代码。熊猫准许对需要 JS 解析的页面,执行 JS 解析,获取 JS 解析后的实际材料。鉴于执行 JS 解析的速度效率很低,因此熊猫内置了智能判断功能,自动检查是否需要对被收集的页面执行 JS 解析,如果不需要的,尽量不运用低效的 JS 解析模式。
6、多模板自动适应本领,很多网站的 “材料页面” 会存在多个不同种类的模板,因此熊猫收集工具允许每个收集项目可以同时设置多个材料页面参考模板,在收集运行时,系统会自动匹配寻找最合适的参考模板用来分析材料页面。
7、实时帮助窗口,在收集项目设置环节,系统会在窗口右上显示与当前配置相关的实时帮助材料,为使用新手提供实时帮助。因此熊猫收集工具的使用可以轻松上手。配合全程智能化辅助本领,即便是第一次接触熊猫收集工具,也可以较轻松完成收集项目的配置工作。
8、正文和回复材料一同收集的本领,典型如论坛页面,正文材料在前,若干回复材料在后,或者还存在若干个回复分页存在。熊猫收集可以将这些作为一个 “目标” 来对待,一并一同完整收集,其配置过程也非常简便。
9、分页材料的轻松整合,准许各种类型的分页模式,使用者只需要做两步就可以完成分页材料的整合:鼠标点选确认分页链接所在,将需要分页整合的字段项勾选上 “分页整合” 项即可。如果页面内具有重复子项存在,则能自动在分页中寻找该重复子项,隐含自动进行分页材料整合,典型如上述的论坛例子,分页页面内的回复材料,可自动完成归并,此时使用者只需要鼠标点选确认分页链接所在即可。有些场合下,在论坛材料页面的分页中也会同时出现主体(主表)材料,此时系统会自动进行判断,不会将主表材料当成重复子项的子表材料进行收集。
10、利用 cookie 方式模拟登录网站,对于需要登录才能访问收集页面的网站(包括 Discuz 等各类型论坛),可以利用账号进行模拟登录。熊猫收集可以通过模拟浏览器机制,利用动态 cookie 和网站进行 cookie 动态对话。有些网站,为了加强数据的安全性,利用 cookie 对网页材料数据进行加密,此时就需要运用熊猫收集特有的 “动态 Cookie” 功能。
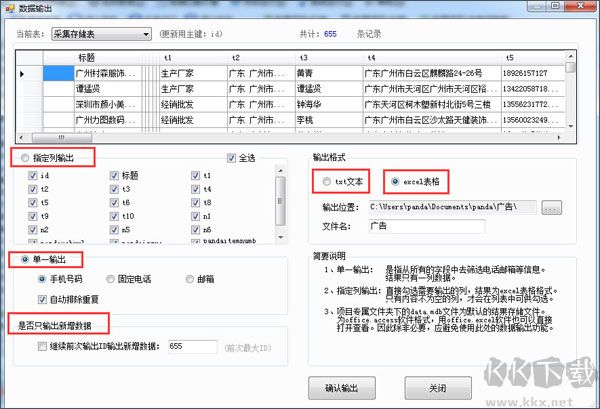
11、准许常见类型数据库引擎。准许 FTP 上传,目前版本的熊猫,准许 Access/mssql/mysql/Oracle 四种常用数据库类型,以后可能会视需求进行扩充。准许将保存的各类文件图片等一同 FTP 上传到远程服务器内。使用者利用此项功能就可以将在本地电脑上收集的数据一同更新到自己网站内,充实栏目材料。对于其他的动态数据发布方式,熊猫会在使用者使用反馈的基础上尽快完成。
12、无人值守自动定时运行,具备更新收集访问的本领,自动定时更新运行。无需人工干预,系统自动封闭运行。
13、文字材料的 “伪原创” 修改。准许文章时间的提前,具备文字材料的 “伪原创” 修改。还可以将文章时间做 “提前” 修改,文章的发表时间是搜索引擎用来区别文章是否原创的一个参考因素。
熊猫智能采集电脑版功能
1、大数据收集
熊猫具备极高的收集速度和效率,是大数据收集场合的最优选择。同时熊猫独有的海量数据处理本领,可以应付大数据收集的需要。是大数据收集场合的首选。
2、舆情监测
借助全部中文搜索引擎,轻松完成全网舆情信息的监测,信息覆盖面广。对于需要重点监测的网站,只需要录入网址即可完成监测。PC 端独立运行,普通的移动 PC 即可胜任舆情监测工作。同时熊猫智能收集监测引擎,也是第三方舆情系统内置爬虫的首选。
3、招标信息监测
利用熊猫智能收集监测引擎,可以轻松完成对招标信息发布网站的最新招标信息进行监测。熊猫收集,是招标信息监测工具的最优选择:操作容易、维护简单、结果直观方便。
4、客户资料收集
利用熊猫可以轻松从网络中批量获取需要的客户信息,利用熊猫的各类绕开防收集机制(如熊猫独有的云收集功能),可以轻松绕开被收集网站的防收集机制。如 58、赶集、百姓网、阿里巴巴、慧聪等等。
5、众多站长:网站搬家、网站材料自动填充
熊猫是操作最简单的收集器,是众多网站站长的首先。同时熊猫也是功能复杂的收集器,可以应用几乎所有的复杂网站的收集、搬家操作。
6、收集互联网资源
利用熊猫收集工具,可以将互联网资源完成批量、格式化的下载到本地。可选的收集工具实在太多了,但都属于 DOS 时代,操作繁琐、作用简单、需要专业技术人员才可以勉强操作。而熊猫不同,全程可视化鼠标操作,操作简单,且功能全面,尤其熊猫可以完成非常复杂的收集需求,不懂技术的人也可以轻松操作。熊猫收集是收集工具的换代产品,—— 轻松收集,从熊猫开始!
7、充实使用者网站材料
使用者可以利用熊猫,将互联网上零散或集中的资源批量收集拷贝到自己网站内,充实自己网站材料。不需要懂技术、不要资金、不要人力投入、借助熊猫,任何人都可以轻松成为一个大站的站长。
8、行业垂直搜索引擎
利用熊猫收集,配合熊猫收集配套的分词索引检索系统,使用者就可以轻松构建一个行业垂直搜索引擎。例如招聘、人才、房产、旅游、购物、商务、分类信息、二手、医疗健康等等。
熊猫收集工具,从开发伊始,就是为了做通用搜索引擎而设计,如果仅仅认为熊猫只是原始而廉价的收集工具,那就是对熊猫大误解。熊猫收集的技术,是源于熊猫精准搜索引擎。
9、作为相关工具的功能配套
可以作为舆情、监控、情报等互联网相关工具的配套工具,节约重复高成本开发,关键是可以提高使用者的使用体验,提升工具自身的技术形象。
熊猫智能采集电脑版亮点
1、搜索引擎解析内核
熊猫利用的是搜索引擎的智能解析内核,完成对网页材料的仿浏览器解析、拆分、材料提取、近似页面比对等等。
2、内置分词 / 索引 / 检索引擎
工具内置有熊猫独立研发的分词索引检索引擎,用于文章的分词、文章材料相似度的分析匹配,摘要自动生成等应用。性能强悍,内存占用小,效率极高。
3、视觉模拟技术
熊猫收集工具会模拟人的视觉来分析网页,在此基础上利用参考(模板)页面完成收集匹配工作。
4、网站页面逻辑关系分析技术
这是熊猫特有的原创技术。是熊猫收集工具所依赖的基础技术之一。

 NetTool IP配置工具
NetTool IP配置工具 ProxyPin
ProxyPin 关关小说采集器
关关小说采集器 京麦工作台(京东商家助手)
京麦工作台(京东商家助手) 哆点正式版
哆点正式版 HEVC视频扩展免费版
HEVC视频扩展免费版 宽带自动拨号王(adsl拨号软件)
宽带自动拨号王(adsl拨号软件) MPC AdCleaner官方正版
MPC AdCleaner官方正版